Technical Implementation
Initialize Database
When a user submits a GitHub repository through the frontend, a Langchain InMemory Vectorstore and a Neo4j instance are spun up, ready to store data as soon as preprocessing wraps up.
Data Preprocessing
The raw code from the repository is first processed into natural language to make it easier to work with. From there, the data is inserted into both the graph database and the vectorstore. Different strategies are used to generate the text for each system, tailoring the structure and content to match the specific role of each database — ensuring the graph database captures meaningful relationships, while the vectorstore is optimized for efficient retrieval and semantic understanding.
GraphDB
The source code is converted into natural language descriptions suitable for building a GraphRAG system, with specific attention given to clearly specifying the type of each node and including the full path.
This step is critical because graph transformers, when processing raw code directly, do not inherently understand that class names represent classes, or that function names represent functions. For example, a function named remove_duplicates might be mistakenly treated as a general “concept” rather than correctly recognized as a function, unless the natural language description explicitly states it.
Each module is processed separately to ensure that all fine-grained details are captured. Handling modules individually is important because longer text inputs reduce the ability of the transformer to detect meaningful relationships between entities.
However, processing modules in isolation makes it harder to identify connections between modules, such as imports and cross-references. To solve this, the full names—including the module paths—must be preserved during translation.
An example of the natural language translation is:
deduplication.bloom_filter.BloomFilter is a class defined in the module deduplication.bloom_filter.After these natural language descriptions are created, a graph transformer is used to generate nodes and relationships, which are then inserted into a Neo4j database.
VectorDB
The preprocessing required for building the vector database is relatively lightweight compared to the more involved process of generating data for the graph database. To prepare the content for the vector store, code snippets are first passed through a translation step, where they are converted into detailed natural language explanations. This process is similar to submitting raw code to a large language model and asking it to produce a thorough, step-by-step breakdown of the code’s structure and behavior. Once translated, the explanations are concatenated into larger blocks of text, segmented into smaller, manageable chunks to optimize downstream retrieval. These chunks are then embedded and stored in an in-memory vector database, enabling fast and efficient semantic search.
Agentic Workflow (Process User Input)
The supervisor agent manages the conversation flow by deciding the next step based on the current state. It prepares the input by adding a system prompt to the conversation history, providing context for the language model. It then asks the model for a structured output, which suggests whether to move to a “macro,” “micro,” or “finish” state. If the model responds with “FINISH,” the agent maps it to an internal END marker for consistency.
After making the decision, the supervisor generates an AI message explaining the chosen route and appends it to the conversation history. Finally, it returns a Command object that tells the system where to go next and includes the updated messages. In short, the supervisor reads the conversation, picks the next action, and records its reasoning clearly for the user or system to see.
Micro Agent
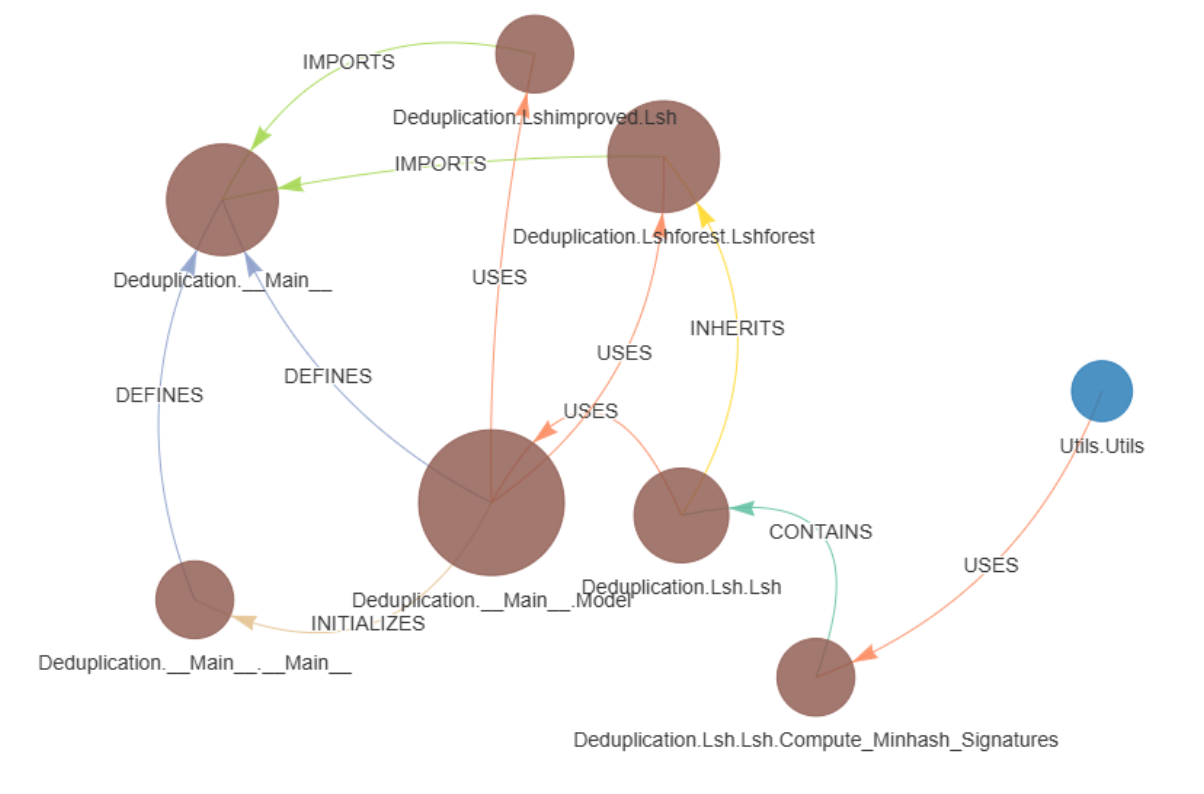
The purpose of the micro-agent is to assist end users in understanding the finer details of the codebase. Users can ask questions about modules, classes, methods, functions, and packages. What sets this agent apart is its ability to provide a full answer by performing both GraphRAG and RAG for a single answer. It traces functional connections by generating Cypher queries and retrieving insights from a graph database, and using these relationships as a foundation, the agent can further enhance its responses either by performing a vector search on a vector store—containing natural language explanations of the code—or by generating visualizations of the functional connections.
The micro-agent is equipped with three key tools, each serving a distinct role:
- Cypher Query Chain (GraphRAG)
- Input: User request
- Process: Generates a Cypher query based on the user’s input (received from the frontend)
- Output1: Retrieves the relevant relationships and nodes from the graph database
Example) { 'path': [{'id': 'Utils.Utils'}, 'IMPORTED_FROM', {'id': 'Utils.Utils.Unionfind'}, 'DEFINES', {'id': 'Utils.Utils'}, 'IMPORTED_FROM', {'id': 'Utils.Utils.Minhash'}, 'USES', {'id': 'Utils.Use_Cases.Nearest_Neighbor_Search'}, 'IMPORTED_IN', {'id': 'Deduplication.__Main__'}] }- Output2: Converts the retrieved relationships into clear, natural language explanations
Example)
`Utils.Utils` imports `Utils.Utils.Minhash`,
which is used in `Utils.Use_Cases.Nearest_Neighbor_Search`
and is imported into `Deduplication.__Main__`- Text Generation (RAG)
- Input: Output2 from the Cypher Query Chain tool
- Process: Searches the vector database for semantically similar documents and enriches the initial relationship explanations with broader context
- Output: A fully developed text response that describes both the relationships and the functionality in depth
Example) The `Utils.Utils` module plays a crucial role in the `Deduplication.__Main__` module by providing fundamental utilities that aid in document deduplication and nearest neighbor search operations. Here's an overview of their relationship: 1. **Union-Find Operations**: The `UnionFind` class in `Utils.Utils` offers efficient set operations important for managing clusters of duplicates and merging them, which is essential for deduplication. - Visualization Generation
- Input: Output1 from the Cypher Query Chain tool
- Process: Uses the retrieved graph data to create visual representations
- Output: A final visualization that illustrates the relationships between nodes, helping users quickly grasp the structure and connections within the code
Macro Agent
The macro agent is designed to give users a high-level understanding of the entire codebase. Instead of relying on a traditional Retrieval-Augmented Generation (RAG) approach, it uses a Context-Augmented Generation (CAG) pipeline. This method allows the agent to deliver a more coherent and contextually rich summary in a single, streamlined response. By having access to the full codebase along with its structural layout, the macro agent can generate summaries that not only capture individual components but also highlight how they fit together across the repository.
The macro agent is equipped with two primary tools, each serving a distinct purpose:
- Summary text generator
- Input: User request + entire codebase + repository tree
- Process: prompt engineered to provide text suitable for mermaid graphs
- Output: Summary of entire codebase
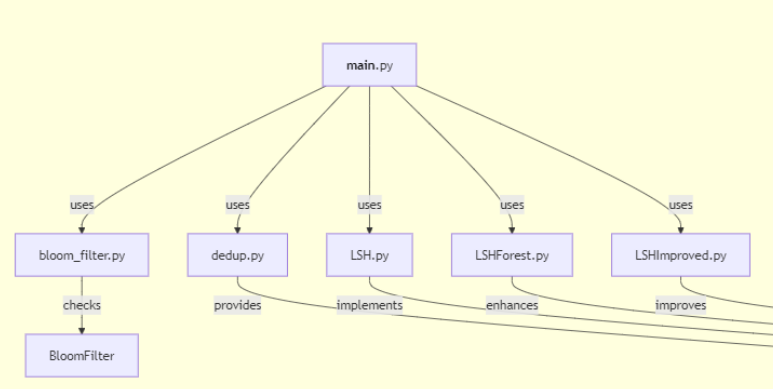
Example) #### Main Modules & Purposes: 1. **deduplication/** - **bloom_filter.py**: Bloom Filter implementation for efficient set membership checks. - **dedup.py**: Baseline deduplication using hash comparisons and token overlap. - **LSH.py**: Locality Sensitive Hashing with MinHash for duplicate detection. - **LSHForest.py**: Uses multiple trees for robustness in LSH-based detection. - **LSHImproved.py**: Multi-probe techniques in LSH to improve efficiency. - Mermaid graph generator
- Input: Output of the summary text generator tool
- Process: Natural language is translated to mermaid graph.
- Output: Mermaid graph generated of funcitonalities of the codebase.
Technical Decision Rationale
Why Neo4j over Memgraph provided by LangChain?
Initially, we considered using Memgraph’s in-memory graph database for the pipeline. However, during testing, we discovered that Memgraph did not fully support the latest Cypher query syntax, particularly when working with a Cypher query generator. This limitation led us to choose Neo4j, which reliably supports the most up-to-date Cypher grammar and provides a robust foundation for our graph-based analysis.Why GPT models over Claude?
While Claude models are often praised for their code generation capabilities, we found that GPT models excelled in linguistic tasks, particularly in retrieving nodes and relationships for graph construction. Their superior performance in understanding and processing natural language made them the ideal choice for our system.Why GPT-4.1 Mini over GPT-4.0?
To optimize the data preprocessing and loading pipeline, we parallelized API calls to improve efficiency. However, GPT-4.0’s token-per-minute (TPM) limit of 30,000 significantly restricted our ability to make multiple concurrent calls. GPT-4.1 Mini, with its much higher TPM limit of 300,000, allowed us to maintain the advantages of GPT models while achieving a substantial performance boost.Why a manual Cypher RAG chain instead of LangChain’s pre-built
GraphCypherQAChain?
We opted to build a custom pipeline for generating, executing, and retrieving Cypher queries rather than using LangChain’s pre-builtGraphCypherQAChain. This decision was driven by the need for greater customization, such as modifying system prompts and providing specific examples to enforce a strict format for Cypher queries. This tailored approach ensured that our pipeline could handle the unique requirements of our graph-based system effectively.